We explore whether surgical manipulation tasks can be learned on the da Vinci robot via imitation learning. However, the da Vinci system presents unique challenges which hinder straight-forward implementation of imitation learning. Notably, its forward kinematics is inconsistent due to imprecise joint measurements, and naively training a policy using such approximate kinematics data often leads to task failure. To overcome this limitation, we introduce a relative action formulation which enables successful policy training and deployment using its approximate kinematics data. A promising outcome of this approach is that the large repository of clinical data, which contains approximate kinematics, may be directly utilized for robot learning without further corrections. We demonstrate our findings through successful execution of three fundamental surgical tasks, including tissue manipulation, needle handling, and knot-tying.
We explore whether surgical manipulation tasks can be learned on the da Vinci Research Kit (dVRK) system via imitation learning. We consider three tasks for automation, including lifting tissue, needle pickup and handover, and suture knot-tying, as shown below. We also explore the use of wrist cameras and evaluate their impact on performance.
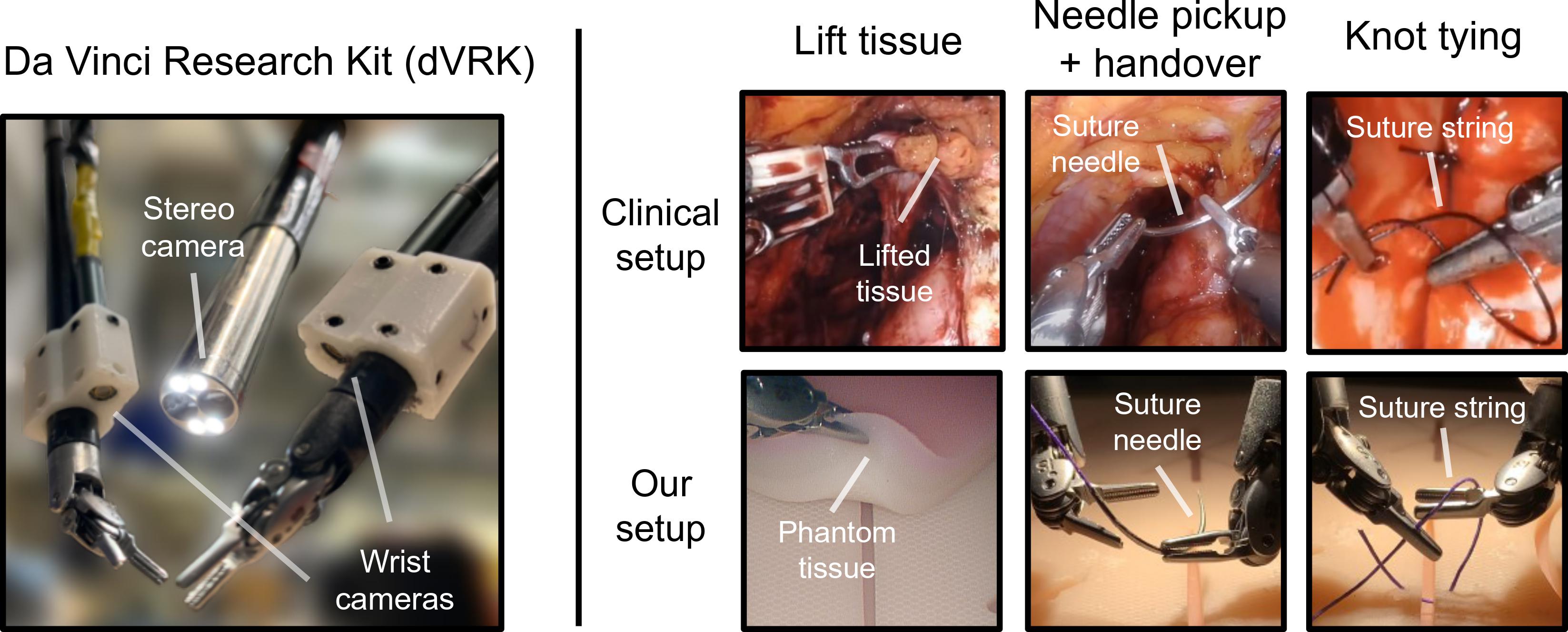
However, robot learning on the da Vinci presents unique challenges. The hardware suffers from inaccurate forward kinematics due to potentiometer-based joint measurements, hysteresis, and overall flexibility and slack in its mechanism. These limitations result in the robot's failure to perform simple visual-servoing tasks (see [1] , [2]). As we discover in this work, naively training a policy using such approximate kinematic data almost always leads to task failure. For instance, a policy trained to output absolute end-effector poses, which is a common approach to train robot policies, achieves near-zero success rates across all tasks.
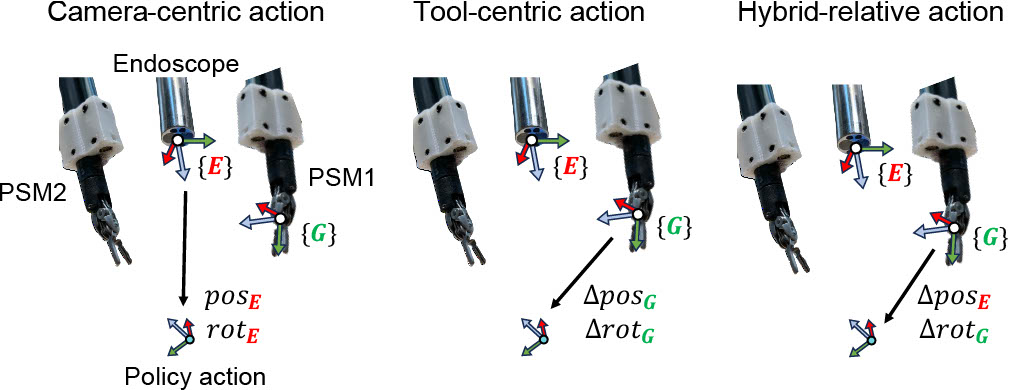
We find that the relative motion of the da Vinci system is much more consistent than its absolute forward kinematics. We thus model policy actions as relative motion, and further explore its variants to design the most effective action representation for the da Vinci. We consider three options as shown below: camera-centric, tool-centric, and hybrid-relative actions. The camera-centric action representation is a baseline approach which models actions as absolute poses of the end-effectors with respect to the endoscope tip. The other two are relative formulations defining actions with respect to the current tool (i.e. end-effector) frame or the endoscope tip frame.
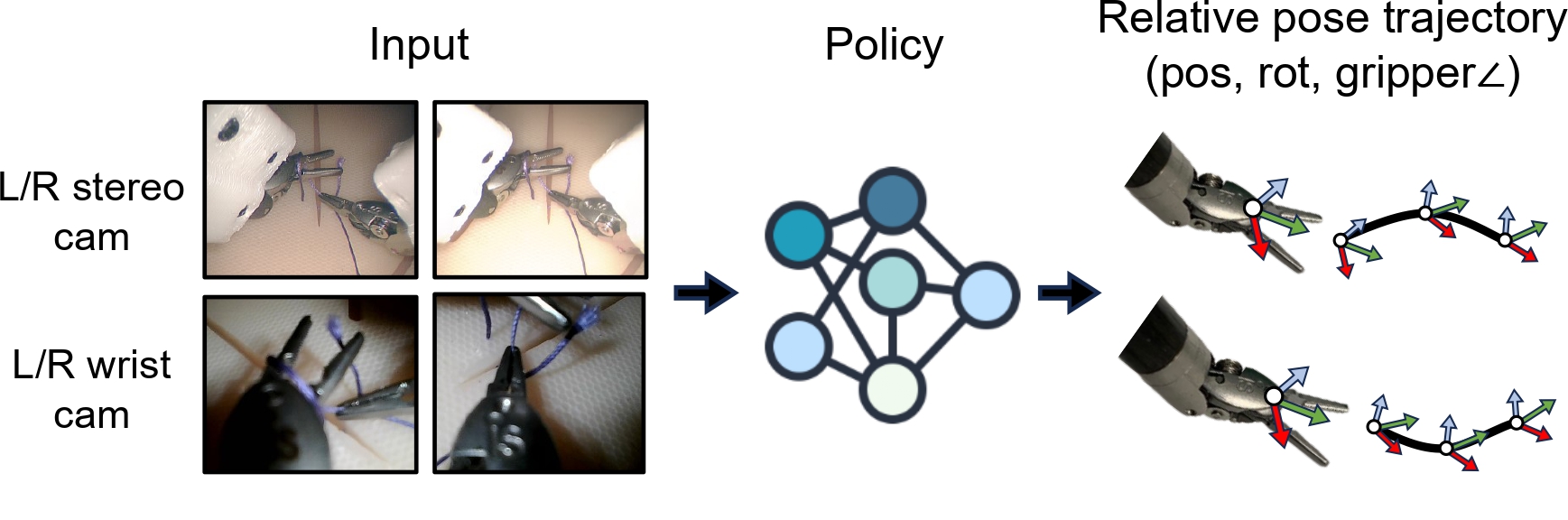
We then train a policy using images as input and the above action representations. We do not use kinematics data as input as done in many prior works, since the kinematics data of the da Vinci can be unreliable. We base our model on ACT, a transformer-based architecture.
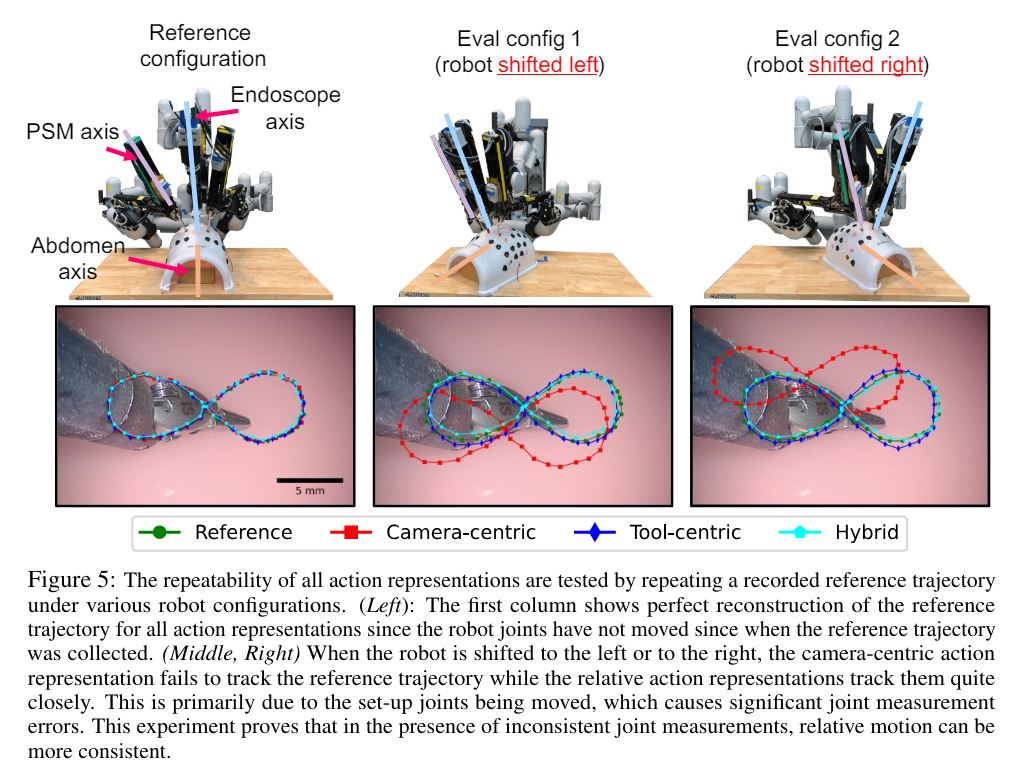
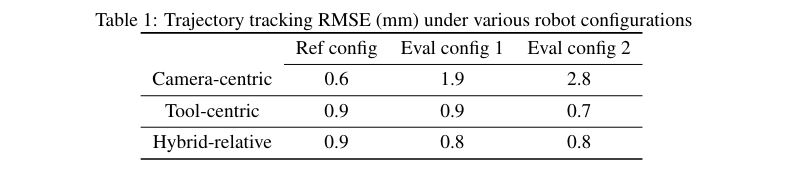
We first evaluate whether relative motion on the da Vinci is more consistent than its absolute forward kinematics. This is evaluated by repeating a recorded reference trajectory using absolute vs relative action formulation under various robot configurations. Overall, our experiments show that in the presence of joint measurement errors, relative motion is more consistent. Therefore, modeling policy actions as relative motion is a better choice. More experiment details and results can be found in the below figure and table.
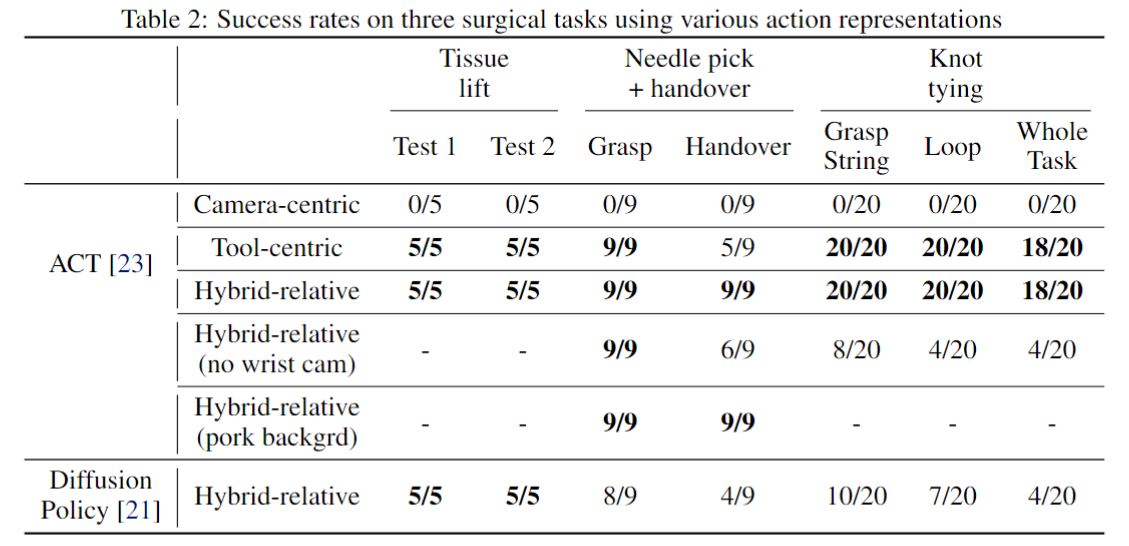
We also evaluate the task success rates of our models trained using the various action representations. Our results show that policies trained using relative action formulations perform well (tool-centric and hybrid-relative action representations), while policies trained using absolute forward kinematics fail. The successful policy rollouts by the hybrid-relative action formulation is shown in the series of videos above. We also observe that wrist cameras can provide significant performance gains in learning surgical manipulation tasks.
The videos below show the results for policy trained using the absolute forward kinematics of the arms (camera-centric actions), which is the baseline approach. Due to the errors in the da Vinci arm foward kinematics, which can change significantly between training and inference, the policies fail to complete the tasks. All videos are 2X speed.
@inproceedings{kim2024srt,
author = {Ji Woong Kim and Tony Z. Zhao and Samuel Schmidgall and Anton Deguet and Marin Kobilarov and Chelsea Finn and Axel Krieger},
title = {Surgical Robot Transformer (SRT): Imitation Learning for Surgical Tasks},
year = {2024},
}





